Day 16
I went for a walk in sunshine yesterday, thought about things and decided to give pagefind a try. Having played about with it, I think it will meet the needs of a typical user. It is not entirely built for what I am using it for, so some templating changes are going to be needed.
I am impressed with how fast hugo builds the content, and the indexing speed. ~5800 pages in under 6 seconds, with 13.9 seconds to build the index. This will make deploying it once a month straightforward. At 10,927 files in total, this set-up could absorb another 30 years of OSIC decisions without my needing to move off the CF free plan.
I might be able to pull off bringing a minimal version of this online, with the only cost being the domain registration and eventual ICO fee.
It was a really great feeling to see it all fit together and fill out with the placeholder data. I may remove some aspects before launch, and some of the styling is a bit janky, but having something like this has been a long time vision of mine. It is deeply satisfying to watch it become real.
The decision search is lightning quick and allows sensible filtering. 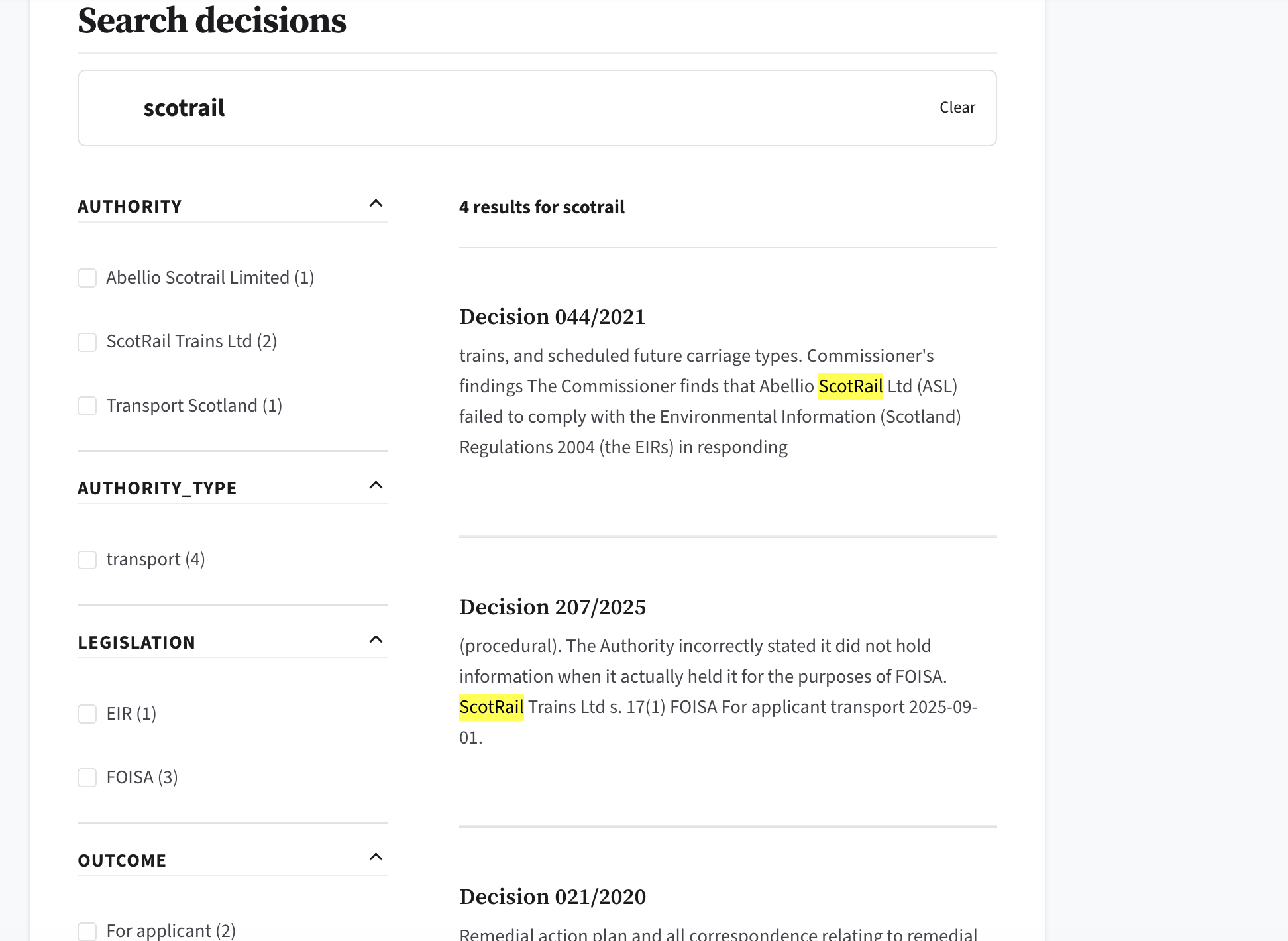
The decision pages show the extracted PIT information per exemption without anyone needing to sift through the entire text. 
It also shows exemption by exemption outcomes (unlike the ICO, OSIC don’t do this) 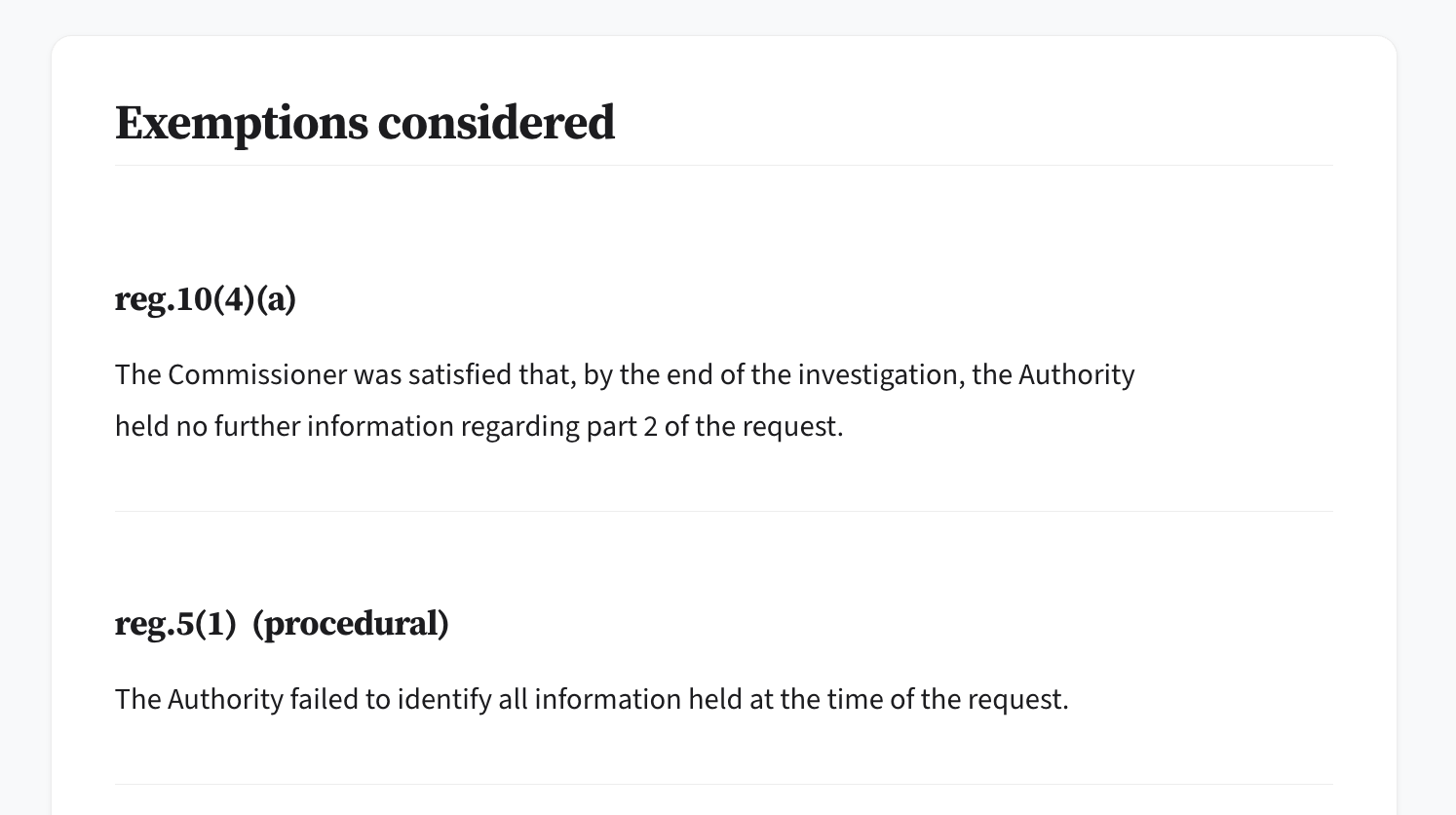
You can also see the key/most interesting thing each decision found. 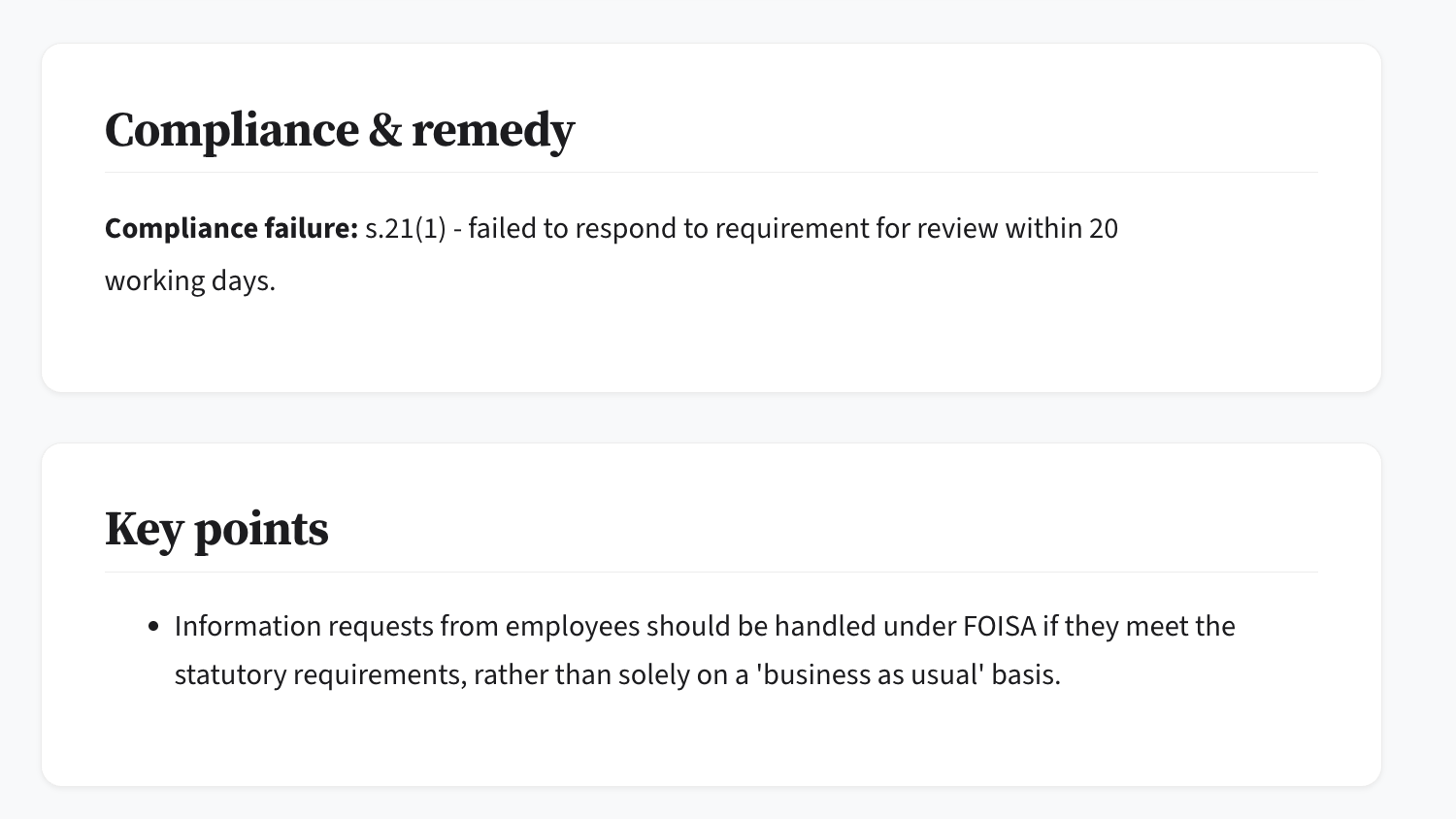
Some of these things were extracted with AI and need further verification. This is a huge task for the backlog, but given the low number of decisions in a year, is much more manageable moving forward. This is going to be the bulk of the work from now until launch. I’ll add the customary cop out disclaimer to this part too. From the sampling I did when deciding how feasible this was, the data seems good enough.
I also wanted to see what it would look like to fill out the authority pages with links to FOI releases. 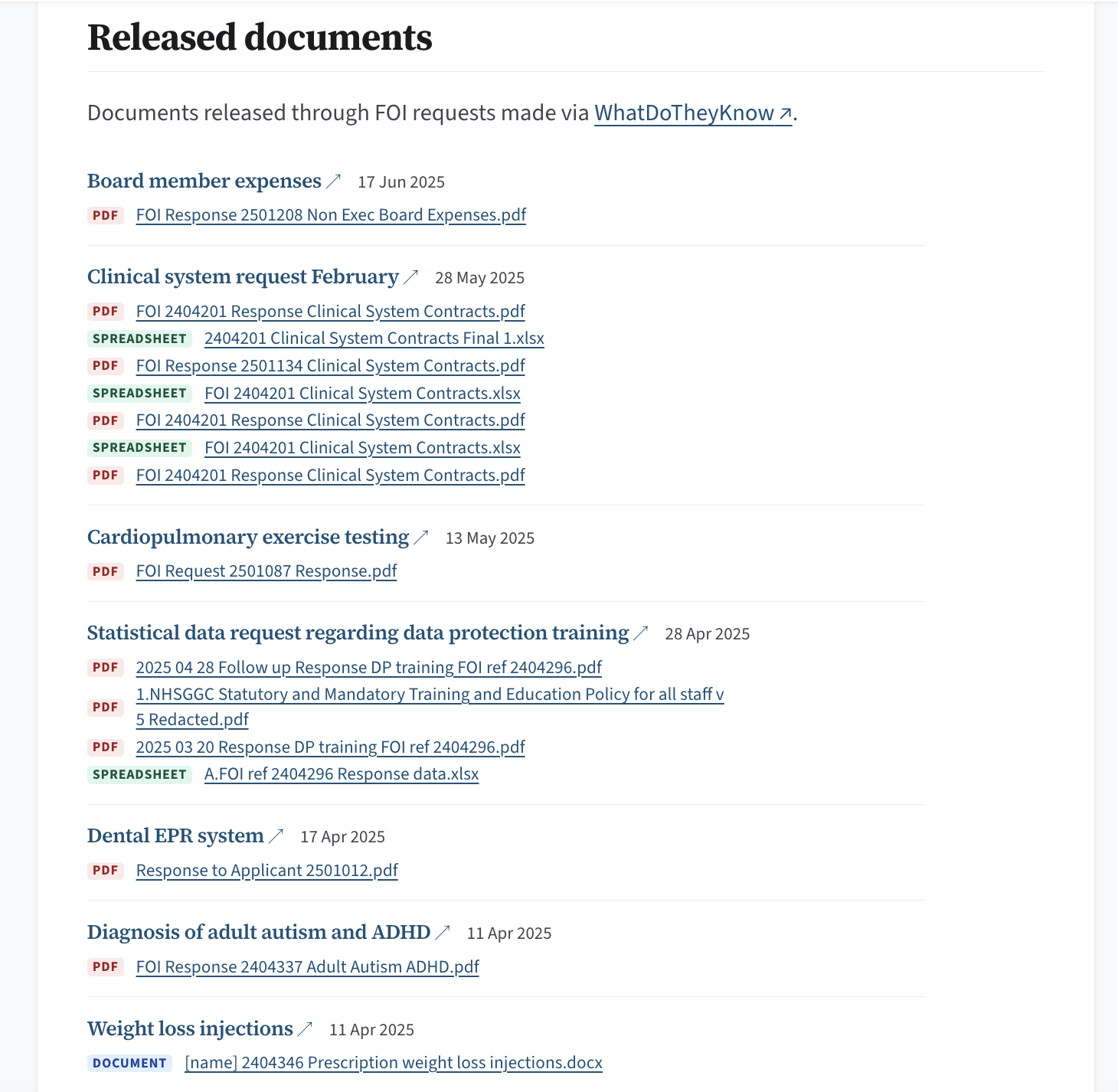
I spiked this out with direct links to the data where there has been a substantive release on WhatDoTheyKnow. They don’t index attachments in a way that lets you browse them like this, so I had to build my own. I redacted requester names from the visible filenames using presidio, then filtered out acknowledgements, refusals, internal reviews, legal notices with a swarm of 16 Sonnet agents working off filenames alone. It won’t be perfect, but I don’t need it to be at this point.
It feels a bit too messy and risky to auto-publish, so I might drop this. My idea was to merge this with data from the disclosure logs that I scraped last year, and bring everything together in one place. There would be OSA things to consider were I to go in that direction, so it is probably one for phase 2.
I keep being reminded of something Zarino said at TICTeC last year that I cheered from my desk at the time - prototyping things and moving fast is just accessible now.
I should build more stuff